Get the Access token and copy to the api_key variable below.
Next, choose the files you want to download and use function googledrive_download() to generate the curl command and download the files.
Here I set the default location of downloaded file to "/scratch/nhh/sec/" and you can update to your own.
The code below only needs to be run once. Alternatively, you can use system(<!-- the curl command -->) inside the for loop to save the storage space.
Code
# curl -H "Authorization: Bearer ya29.a0AcM612zWU6Da_xDydbg-ZDc6vBpMBUoYBTO44oTpTeDvHOhzOyjMr66xdIO7nCfclFiE_NdjSJZvdpFWsNoj2Ds-7L8O2jnrJ15I3MfYb4vlsPcxFj0tPx8Mr8MIa081ZnoIXWnvft6D4aQ1qjda4LyoCl1j0iYuNPKrN3jfaCgYKAS8SARMSFQHGX2Mi8_vM15q895m7oulKDmaIrw0175" https://www.googleapis.com/drive/v3/files/10Fi5SU5LVUGq1oJz1iPWpCMwa_eAdnjD?alt=media -o /scratch/nhh/sec/10-X_2019.zip## function to automatically generate the downloading code googledrive_download <-function(api_key, file_info, file_link, file_name, to ="/scratch/nhh/sec/") {if (missing(file_info)) { # if argument `file_info` is not provided cmd_output <-paste('curl -H "Authorization: Bearer ', api_key, '" ', "https://www.googleapis.com/drive/v3/files/", file_link, "?alt=media -o ", to, file_name, " ", sep ="") } else {# if argument `file_info` is provided if (is.data.frame(file_info) &dim(file_info)[2] ==2) { cmd_output <-paste(apply(X = file_info, MARGIN =1, FUN =function(x) paste('curl -H "Authorization: Bearer ', api_key, '" ', "https://www.googleapis.com/drive/v3/files/", x[1], "?alt=media -o ", to, x[2], sep ="") ), collapse ="; " ) } else {stop("Error: 'file_info' parameter is not data.frame object or has more than 2 columns.") } }return(cmd_output)} api_key ="ya29.a0AcM612xRrh1wolCu4ufaTDwkJqXerA0HA6CyTgLUtQJ6V0JyWeZnlCF7oYx2R8CZ9KhwFPfrdvFPG2WKcAS_8GVK_ve7VvIg-HZAxiD2Xhx4vnUcYLgWtSLMRPzdUnJS_3YmO2CDHVhY8UQDmYmJKsvkmtSElGdLqxKON64laCgYKAaISARMSFQHGX2Mi8eNrVwx4jsGnn9JrhKkexA0175"googledrive_download_cmd <-googledrive_download(api_key, file_info = googledrive_links[1, 2:3])## directly run the code in the console, instead of in the terminal system(googledrive_download_cmd)list.files(path ="/scratch/nhh/sec/", pattern =".zip") ## unzip one of the .zip file utils::unzip(zipfile ="/scratch/nhh/sec/10-X_2019.zip", exdir ="/scratch/nhh/sec/")
S2. Look and Read the SEC filings.
To understand the information contained in the name of the csv files, please refer to the “Paths and directory structure” section in Accessing EDGAR Data
Central Index Key (CIK): EDGAR assigns to filers a unique numerical identifier, known as a Central Index Key (CIK), when they sign up to make filings to the SEC. CIK numbers remain unique to the filer; they are not recycled. It is named as CIK in the cleaned dataset.
Accession number: For example, 0001193125-15-118890 is the accession number, a unique identifier assigned automatically to an accepted submission by EDGAR. The first set of numbers (0001193125) is the CIK of the entity submitting the filing. This could be the company or a third-party filer agent. Some filer agents without a regulatory requirement to make disclosure filings with the SEC have a CIK but no searchable presence in the public EDGAR database. The next two numbers (15) represent the year. The last series of numbers represent a sequential count of submitted filings from that CIK. The count is usually, but not always, reset to zero at the start of each calendar year. It is named as accession_num in the cleaned dataset.
Code
# list of files in the folder sec_csv <-list.files("/scratch/nhh/sec/2019", recursive=TRUE, full.names =TRUE)# set.seed(123); csv_sample <- sample(sec_csv, size = 10)# extract the list directly from .ZIP file sec_csv2 <-unzip(zipfile ="/scratch/nhh/sec/10-X_2019.zip", list =TRUE) %>%grep(pattern =".txt$", x = .$Name, value = T)# extract filing name information using `sec_filing_nameinfo()`sec_csvinfo <-sec_filing_nameinfo(file_path = sec_csv2, keep.original =TRUE) %>%as_tibble() %>%mutate(filing_date =as.Date(x = filing_date, format ="%Y%m%d"))## tabulation: Table 2set.seed(123)gt(sample_n(sec_csvinfo, size =10)) %>%tab_header(title ="Information from File Paths of .Zip Files",subtitle =md("File: 10-X_2019.zip \u2192 Variable: `sec_csvinfo`") ) %>%tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() ) %>%tab_style(style =cell_text(size =px(8)), locations =cells_body(columns =c(full_path)) ) %>%cols_width( filing_date ~cm(30) )
After getting basic information from the title of the SEC filings, we now will import the .txt file and parse required information.
s2.1. Import 10-K Filings and Familiarise the Structure
Code
## keep the universe of 10-K filingssec_10konly <- sec_csvinfo %>%filter(grepl(pattern ="10-K", x = file_type, fixed = T))## get the 10-K for Apple Inccat(paste("Apple Inc.>", sec_10konly %>%filter(CIK =="320193") %>% .$full_path, collapse =" "))
Apple Inc.> 2019/QTR4/20191031_10-K_edgar_data_320193_0000320193-19-000119.txt
To extract the purchasing/outsourcing contract information as in Moon and Phillips (2020), we only need to look at 10-K filings. Currently, all 10-X filing types include 10-K, 10-K-A, 10-KT, 10-KT-A, 10-Q, 10-Q-A, 10-QT, and we will drop all 10-Q related filings.
This step significantly reduce the number of observations we need to examine. For instance, the total number of 10-X filings in 2019 drops from 27,014 in sec_csvinfo to 7,944 in sec_10konly.
Here I start with the file 2019/QTR4/20191031_10-K_edgar_data_320193_0000320193-19-000119.txt to demonstrate.
s2.1A. Header Info in 10-K Filings
Code
## read .txt files into the R environment # filing_path <- sec_10konly$full_path[1]filing_path <- sec_10konly %>%filter(CIK =="320193") %>% .$full_path # Apple Inc: // 2488## testing candidcates: ## [ ]: https://www.sec.gov/Archives/edgar/data/1173281/000138713119000051/ohr-10k_093018.htm#ohr10k123118a010## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/831641/000083164120000154/ttek-20200927.htm (table is more complex) ## [ ]: https://www.sec.gov/Archives/edgar/data/320193/000032019323000106/0000320193-23-000106.txt ## [ ]: https://www.sec.gov/Archives/edgar/data/1045810/000104581020000010/nvda-2020x10k.htm#s82E07D2E693B525F8500B3A76673C74A## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/1652044/000165204424000022/goog-20231231.htm > Alphabet Inc. ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/2488/000000248824000012/amd-20231230.htm > AMD > search "purchase commitments" ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/1543151/000154315124000012/uber-20231231.htm > [Uber Tech. > Purchase Commitment in Text] ### Tables in Notes under Item 8. ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/0001730168/000173016823000096/avgo-20231029.htm > [Broadcom Inc. > The table is not under Item 7, but under Note 13.] ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/1090727/000109072724000008/ups-20231231.htm > [UPS > Table is under Item 8, Note 9]# filing <- readLines(con = filing_path) filing <-readLines(archive::archive_read("/scratch/nhh/sec/10-X_2019.zip", filing_path))## create a more structured file for the main body of the document filing_structured <- filing[(grep("<DOCUMENT>", filing, ignore.case =TRUE)[1]):(grep("</DOCUMENT>", filing, ignore.case =TRUE)[1])] %>%paste(., collapse =" ") %>%str_squish() %>%clean_html2(input_string = ., pattern ="(</[^>]+>\\s*</[^>]+>\\s*)<([^/])") %>%# *updated Oct 10, 2024 as.vector() ## keep only the plain text in each section filing_cleantext <-sapply(X = filing_structured,FUN =function(x) html_text(read_html(x), trim =TRUE), USE.NAMES =FALSE)## get the filing headers filing_header <-filing.header(x = filing)### tabulate the header information gt(as.data.frame(`colnames<-`(filing_header, c("Item", "Input"))) ) %>%# tab_header(title = "Table 3: Header Information in 10-K Filings") %>% tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() )
Table 3:
Header Information in 10-K Filings
Item
Input
ACCESSION NUMBER
0000320193-19-000119
CONFORMED SUBMISSION TYPE
10-K
PUBLIC DOCUMENT COUNT
96
CONFORMED PERIOD OF REPORT
20190928
FILED AS OF DATE
20191031
DATE AS OF CHANGE
20191030
FILER:
COMPANY DATA:
COMPANY CONFORMED NAME
Apple Inc.
CENTRAL INDEX KEY
0000320193
STANDARD INDUSTRIAL CLASSIFICATION
ELECTRONIC COMPUTERS [3571]
IRS NUMBER
942404110
STATE OF INCORPORATION
CA
FISCAL YEAR END
0928
FILING VALUES:
FORM TYPE
10-K
SEC ACT
1934 Act
SEC FILE NUMBER
001-36743
FILM NUMBER
191181423
BUSINESS ADDRESS:
STREET 1
ONE APPLE PARK WAY
CITY
CUPERTINO
STATE
CA
ZIP
95014
BUSINESS PHONE
(408) 996-1010
MAIL ADDRESS:
STREET 1
ONE APPLE PARK WAY
CITY
CUPERTINO
STATE
CA
ZIP
95014
FORMER COMPANY:
FORMER CONFORMED NAME
APPLE INC
DATE OF NAME CHANGE
20070109
FORMER COMPANY:
FORMER CONFORMED NAME
APPLE COMPUTER INC
DATE OF NAME CHANGE
19970808
Code
# ## get the table of contents (toc) # filing_toc <- filing.toc(x = filing, regex_toc = "<text>|</text>") # # browsable(HTML(as.character(filing_toc))) # view the ToC in html format
The function filing.toc() does not necessarily extract the table of contents. Although we can use regex_toc = "<table>|</table>" to get the first table we saw in the .txt file, it may not be the table of contents we want. The function loc.item() is better at identify the item; however, it is not structured to get the full table of contents. We modify function loc.item() and create function loc.item_MDnA() to better extract the item we want.
s2.1B. All Items in 10-K filings
To see the full list of items in a 10-K filing, I look into this file and extract all items. The Table 4 below presents all items included in a 10-K filing.
Code
## This section extract the names of each items in the 10-K filing. # URL of the webpageurl <-"https://www.sec.gov/answers/reada10k.htm"# Set a custom user-agent string to mimic a browseruser_agent_string <-"leonardo.xu@gmail.com"# Read the webpage with the custom user-agentreada10k <-read_html(GET(url, user_agent(user_agent_string)))# browsable(HTML(as.character(reada10k)) )# generate the item text reada10k_items <-html_nodes(reada10k, "table")[3] %>%html_nodes(., "p") %>% .[grep(pattern =">Item\\s+[1-9]", x = ., ignore.case =FALSE)] %>%sapply(X = ., FUN =function(x) { text_raw <-str_squish(html_text(html_nodes(x, "strong, b"))) text_output <-paste(text_raw[text_raw !=""], collapse =" - ") if (!grepl("-", text_output)) { text_output <-gsub("\"|“|”|\u0093", "- ", text_output) } output <-str_replace_all(string = text_output, pattern ="\"|“|”|\u0093|\u0094", replacement ="")return(output) }, simplify =TRUE) %>%str_split_fixed(string = ., pattern =" - ", 2)# tabulate the items gt(`colnames<-`(data.frame(reada10k_items), c("Item", "Content"))) %>%# tab_header(title = "Table 4: Items in the Table of Contents in 10-K Filings") %>% tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() ) %>%cols_width( Item ~cm(30) ) %>%tab_style( # headers to boldstyle =cell_text(weight ="bold"),locations =cells_column_labels() )
Table 4:
Items in the Table of Contents in 10-K Filings
Item
Content
Item 1
Business
Item 1A
Risk Factors
Item 1B
Unresolved Staff Comments
Item 2
Properties
Item 3
Legal Proceedings
Item 4
Item 5
Market for Registrant’s Common Equity, Related Stockholder Matters and Issuer Purchases of Equity Securities
Item 6
Selected Financial Data
Item 7
Management’s Discussion and Analysis of Financial Condition and Results of Operations
Item 8
Financial Statements and Supplementary Data
Item 9
Changes in and Disagreements with Accountants on Accounting and Financial Disclosure
Item 9A
Controls and Procedures
Item 9B
Other Information
Item 10
Directors, Executive Officers and Corporate Governance
Item 11
Executive Compensation-
Item 12
Security Ownership of Certain Beneficial Owners and Management and Related Stockholder Matters
Item 13
Certain Relationships and Related Transactions, and Director Independence
Item 14
Principal Accountant Fees and Services
Item 15
Exhibits, Financial Statement Schedules
From Table 4, Item 7, MD&A, is the item of interest. We need to first locate the whole section of Item 7 and then extract the information from that. The two candidate REGEXs are:
Other long-term liabilities reflected on the registrant’s balance sheet under GAAP.
However, this information is not only disclosed in Item 7, but also in the Note(s) in Item 8. E.g. Apple Inc. 2019 10K.
About the Lack of Consistency in the Reporting Format!
The purchase obligation disclosure is not always tabulated and can sometimes be in plain text. Here is one example from Apple’s 10-K filing in 2023. Even though Apple tabulates these numbers in its previous filings, there is no guarantee that they will continue the same reporting format.
So, we start with Item 7:
function loc.item_MDnA() is created to locate the MD&A section in the 10-K filing.
Code
## Item 7: # cat("Information to locate Item 7 in the 10-K filing:") loc_item7 <-loc.item_MDnA(x = filing_structured, filing_type ="10-K")## Extract the table: ### From Item 7: item7_purchase <-filing.10kitem_purchase(x = filing_structured,loc_item = loc_item7$loc_item, item_regex ="(?=.*purchas)(?=.*(obligation|commitment|agreement|order|contract))")
We can see from variable loc_item7 that Line 947 to 1108 in the cleaned raw HTML variable filing_structured are for Item 7.
Then, we use function filing.10kitem_purchase() to obtain the purchase obligation information in variable item7_purchase. As shown in Table Table 5, the purchase obligations are detailed below. Unit measure, plain text and raw HTML can also be found in item7_purchase.
Table 5:
Purchae Obligation Table in Item 7
item
variable
value1
rank
Deemed repatriation tax payable
D$- Payments due in 2020
—
1
Deemed repatriation tax payable
D$- Payments due in 2021–2022
4,350
2
Deemed repatriation tax payable
D$- Payments due in 2023–2024
8,501
3
Deemed repatriation tax payable
D$- Payments due after 2024
16,655
4
Deemed repatriation tax payable
D$- Total
29,506
NA
Manufacturing purchase obligations
D$- Payments due in 2020
40,076
1
Manufacturing purchase obligations
D$- Payments due in 2021–2022
1,974
2
Manufacturing purchase obligations
D$- Payments due in 2023–2024
808
3
Manufacturing purchase obligations
D$- Payments due after 2024
69
4
Manufacturing purchase obligations
D$- Total
42,927
NA
Operating leases
D$- Payments due in 2020
1,306
1
Operating leases
D$- Payments due in 2021–2022
2,413
2
Operating leases
D$- Payments due in 2023–2024
1,746
3
Operating leases
D$- Payments due after 2024
5,373
4
Operating leases
D$- Total
10,838
NA
Other purchase obligations
D$- Payments due in 2020
3,744
1
Other purchase obligations
D$- Payments due in 2021–2022
2,271
2
Other purchase obligations
D$- Payments due in 2023–2024
572
3
Other purchase obligations
D$- Payments due after 2024
41
4
Other purchase obligations
D$- Total
6,628
NA
Term debt
D$- Payments due in 2020
10,270
1
Term debt
D$- Payments due in 2021–2022
18,278
2
Term debt
D$- Payments due in 2023–2024
19,329
3
Term debt
D$- Payments due after 2024
53,802
4
Term debt
D$- Total
101,679
NA
Total
D$- Payments due in 2020
55,396
1
Total
D$- Payments due in 2021–2022
29,286
2
Total
D$- Payments due in 2023–2024
30,956
3
Total
D$- Payments due after 2024
75,940
4
Total
D$- Total
191,578
NA
1 Unit: in millions
Then, we look into Item 8. We still use function loc.item_MDnA(). Different from searching Item 7, we adjust the two parameters regex_item and regex_num in the function to locate Item 8.
Code
## Item 8: loc_item8 <-loc.item_MDnA(x = filing_structured, filing_type ="10-K", regex_item =c(NA, "(?=.*finan)(?=.*statem)(?=.*supple)(?=.*data)"), # item header regex_num =c("[>](Item|ITEM)[^0-9]+2\\.", "[>](Item|ITEM)[^0-9]+8\\."), # item number regex_perl =TRUE) item8_notes_html <-filing.item8_notes(x = filing_structured, loc_item = loc_item8$loc_item, item_regex ="\\bpurchas[^\\.]*\\b(obligat|commitment|agreement|order|contract)",note_regex =NULL) ## Extract the table: ### From Item 8: item8_purchase <-sapply(X = item8_notes_html, FUN =function(x) {filing.10kitem_purchase(x = x,loc_item =c(1, length(x)),item_regex ="(?=.*purchas)(?=.*(obligation|commitment|agreement|order|contract))")}, simplify =FALSE, USE.NAMES =TRUE)#### further assign each element in the list into a single variable.{for (x inseq_along(item8_notes_html)) {print(paste("item8", letters[x], "_purchase", sep =""))assign(x =paste("item8", letters[x], "_purchase", sep =""),value = item8_purchase[[x]]) } rm(item8_purchase) # remove the collection if it contains more than 1. }
[1] "item8a_purchase"
We can see from variable loc_item8 that Line 1123 to 1701 in the cleaned raw HTML variable filing_structured are for Item 8.
After locating Item 8, function filing.item8_notes() is used to (1) Extract the HTML for Item 8 and create of a Table of Notes (“ToN”). (2) Identify the Note(s) that match the item_regex. Alternatively, the Note(s) can be extracted by note_regex. (3) Return the HTML for the sub-Note in the Note(s) of Interest. The output of function filing.item8_notes() is a list with the name of the element being the Note name and element is a character vector recording the raw HTML for the sub-Note(s).
Additional Notes for function filing.item8_notes()
This additional step of using this function is to extract the header of the sub-Note and use it as the name of the “item” variable in the final output. As you can see from the function name, it is for Item 8 only.
Output item8_notes_html contains information about the matched sub-Note HTML of corresponding Note(s).
Then, we use elements in item8_note_html as the input in function filing.10kitem_purchase() and obtain output item8_purchase, which is a list. We can also choose to rename each element in the list separately. Using code ls(pattern = "item\\d(\\w)*_purchase"), we can find that variables containing purchase obligation information are
[1] "item7_purchase" "item8a_purchase"
As shown in Table Table 6, the purchase obligations are detailed below. Unit measure, plain text and raw HTML can also be found in item8a_purchase.
Table 6:
Purchae Obligation Table in Item 8
item
variable
value1
rank
D$- Unconditional Purchase Obligations
2020
2,476
1
D$- Unconditional Purchase Obligations
2021
2,386
2
D$- Unconditional Purchase Obligations
2022
1,859
3
D$- Unconditional Purchase Obligations
2023
1,162
4
D$- Unconditional Purchase Obligations
2024
218
5
D$- Unconditional Purchase Obligations
Thereafter
110
6
D$- Unconditional Purchase Obligations
Total
8,211
NA
1 Unit: in millions
S3. Up Next!
With all functions presented in this document, I will write the parallel functions to parse information from all files. Let’s start with the 2019 filings.
Here is a list of functions used in the file:
Code
lsf.str()
clean_html : function (input_string, pattern = "(</[^>]+>\\s*</[^>]+>\\s*)<([^/])")
clean_html2 : function (input_string, pattern = "(</[^>]+>\\s*</[^>]+>\\s*)<([^/])")
filing_item7_extract : function (filing_txt, filing_headerid, item_regex = "(?=.*purchas)(?=.*(obligation|commitment|agreement|order|contract))")
filing.10kitem_purchase : function (x, loc_item, item_regex = "(?=.*purchas)(?=.*(obligation|commitment|agreement|order|contract))")
filing.cleaned : function (loc_file, zip_file, text_break_node)
filing.cleaned_errorid : function (cleaned_dt)
filing.cleaned_multiple : function (loc_file, zip_file, text_break_node)
filing.cleaned_parallel : function (loc_file, zip_file, text_break_node, errors = 1)
filing.cleaned_parts : function (cleaned_dt)
filing.header : function (x, regex_header = "ACCESSION NUMBER:|</SEC-(HEADER|Header)>")
filing.item : function (x, loc_item, item_id, item, item_id_backup, reporting_qrt, text_break_node,
table = TRUE, parts = c("footnote"))
filing.item_multiple : function (x, loc_item, item_id, item, item_id_backup, reporting_qrt, text_break_node,
table = TRUE, parts = c("footnote"))
filing.item_purchase : function (x, loc_item, item, item_id_backup, reporting_qrt, item_regex,
table = TRUE, parts = c("footnote"))
filing.item8_notes : function (x, loc_item, item_regex, note_regex = NULL)
filing.toc : function (x, regex_toc = "<text>|</text>")
googledrive_download : function (api_key, file_info, file_link, file_name, to = "/scratch/nhh/sec/")
has_annotations : function (input)
html_to_structure : function (item_html, headerlength = c(1, 8))
html_to_table : function (tbl_html, item_html, tbl_colname, item_regex, allcurrency = TRUE)
item2_html_table : function (item_html, reporting_qrt)
loc.item : function (x, filing_type, regex_item = c("(Unregistered|UNREGISTERED|UNRE\\w+)\\s+(Sale|sale|SALE)(s|S|)\\s*(of|Of|OF)",
"(Market|MARKET)\\s+(for|For|FOR)\\s*(The|THE|the)?\\s*(Registrant|REGISTRANT|registrant|Re|re|RE|CO)"),
regex_perl = TRUE)
loc.item_MDnA : function (x, filing_type = "10-K", regex_item = c(NA, "(?=.*management)(?=.*discussion)(?=.*analysis)(?=.*operation)"),
regex_num = c("[>](Item|ITEM)[^0-9]+2\\.", "[>](Item|ITEM)[^0-9]+7\\."),
regex_perl = TRUE)
sec_filing_nameinfo : function (file_path, keep.original = TRUE)
source.folder : function ()
table.cleaned : function (id_table_raw, text_break_node)
tbl.rowkeep : function (regex_row = "(\\w+(\\s+?)\\d{1,2},\\s+\\d{4}|Total|to|[-]|\\d+\\/\\d+\\/\\d+)|(Jan(uary)?|Feb(ruary)?|Mar(ch)?|Apr(il)?|May|Jun(e)?|Jul(y)?|Aug(ust)?|Sep(tember)?|Oct(ober)?|Nov(ember)?|Dec(ember)?)",
row_name, reporting_qrt)
tbl.rowkeep2 : function (regex_row = "(\\w+(\\s+?)\\d{1,2},\\s+\\d{4}|Total|[^a-zA-Z]to|[-]|\\d+\\/\\d+\\/\\d+)|((Jan(uary)?|Feb(ruary)?|Mar(ch)?|Apr(il)?|May|Jun(e)?|Jul(y)?|Aug(ust)?|Sep(tember)?|Oct(ober)?|Nov(ember)?|Dec(ember)?)\\b)|quarter",
row_name, reporting_qrt)
text_to_table : function (text, var_name, largeunits_regex = "thousand|milli|bill|tril")
text_to_tokens : function (sentences, item_regex)
vectors_to_matrix : function (vec_list)
Code
{## information extraction from function `fling.cleaned()` info <- filing_header selected_headers <-c('ACCESSION NUMBER','CONFORMED SUBMISSION TYPE','PUBLIC DOCUMENT COUNT','CONFORMED PERIOD OF REPORT','FILED AS OF DATE','DATE AS OF CHANGE','FILER:','COMPANY DATA:','COMPANY CONFORMED NAME','CENTRAL INDEX KEY','STANDARD INDUSTRIAL CLASSIFICATION','IRS NUMBER','STATE OF INCORPORATION','FISCAL YEAR END','FILING VALUES:','FORM TYPE','SEC ACT','SEC FILE NUMBER','FILM NUMBER','BUSINESS ADDRESS:','STREET 1','STREET 2','CITY','STATE','ZIP','BUSINESS PHONE') info_cleaned <- info[match(selected_headers, table = info[1:max(grep("mail", info[,1], ignore.case = T)[1]-1, nrow(info), na.rm = T),1]), 2] # all info before section "MAIL ADDRESS:" info_cleaned## generate cleaned info item2_cleaned <-filing.item(x = filing_structured,loc_item = loc_item7$loc_item,item_id = loc_item7$item_id,item = loc_item7$item,item_id_backup = loc_item7$item_id_backup, ## updated August 8, 2023 text_break_node = text_break_node, reporting_qrt = info_cleaned[4],parts ="footnote")}
Notes
All codes here may have issues with pure text documents, i.e. filings are not in the HTML format.
A new set of codes need to be written to identify whether the filing is in HTML or TEXT format.
This situation should be a minority in the whole sample, but still need to be checked.
Appendix
Figure 1: Apple 2019 10-K Contractual Obligations
The footnote (1) in Figure 1 shows that manufacturing purchase obligations are primarily non-cancellable, which indicates that some numbers of the purchase obligations may not cover items consistent with our story.
Figure 2: Tetra Tech Inc. 2020 10-K Contractual Obligations
The underlined paragraph in Figure 3 shows that smaller reporting companies defined under Item 10 of Regulation S-K are not required to disclose contractual obligations under Item 7. You need to find a way to separate these filings from the very beginning to improve the parsing efficiency.
Reference
Source Code
---title: "Repurchasing Contracts from SEC Filings"subtitle: "Collect and Parse 10-Ks"author: "Hongyi Xu"date: "September 16, 2024"date-modified: last-modifiedformat: html: theme: flatly toc: true code-fold: true code-tools: true code-summary: "Show the code" html-math-method: katex toc-location: left code-block-bg: true code-block-border-left: "#31BAE9" execute: output: trueeditor: visualeditor_options: chunk_output_type: console---```{=html}<style type="text/css">body, td { font-size: 16px;}code.r{ font-size: 12px;}pre { /* For appearance of output blocks */ font-size: 12px; background-color: #f0f0f0; /* Light grey background */ padding: 5px; <!-- border-radius: 5px; /* border corner */ -->} .gt_table .gt_caption { font-size: 16px; display: flex; justify-content: space-between; align-items: center;}</style>```The purpose of this file is to replicate the [Moon and Phillips (2020)](https://pubsonline-informs-org.ez.hhs.se/doi/10.1287/mnsc.2019.3443) paper on the purchasing contracts of US public firms.[Cheat sheet](https://evoldyn.gitlab.io/evomics-2018/ref-sheets/R_strings.pdf) for REGEX in R.```{r setup, include=FALSE}knitr::opts_chunk$set(echo =TRUE) # extending file lifes: source: https://wrds-www.wharton.upenn.edu/pages/support/the-wrds-cloud/managing-data/storing-your-data-wrds-cloud/ system("touch /scratch/nhh/sec/*; ls -l /scratch/nhh/sec") source.folder <-function() {# Specify the path to the folder path_to_functions <-"functions"# Get a list of all .R files in the folder r_files <-list.files(path = path_to_functions, pattern ="\\.R$", full.names =TRUE)# Source each filelapply(r_files, source)}## 0. initial setup ---- wd <-"~/BeckerJosephsonXu_2025/Collect_Parse_10Ks"# the main working directory > then easy to go to sub-directories setwd(wd)source("https://hongyileoxu.github.io/research/RepurchaseProject/SEC_web_v3cfunctions.R", encoding ="UTF-8")source("~/BeckerJosephsonXu_2025/Collect_Parse_10Ks/functions_collect_parse_10Ks.R", encoding ="UTF-8")lapply(X =list.files("~/BeckerJosephsonXu_2025/Collect_Parse_10Ks/functions", pattern ="\\.R$", full.names =TRUE), FUN =function(x) {source(x, encoding ="UTF-8")}) ## import self-written functions list.files()lsf.str()text_break_node =read_xml("<table><tr><td> <footnote> </td></tr></table>\n")library(rvest)library(readr)library(tidyr)library(dplyr)library(zoo)library(parallel)library(foreach)library(doParallel)library(stringr)library(lubridate)library(gt)library(httr) # to extract html from edgar library(htmltools) # to view raw html code list.files()```Functions used in following analyses are recorded in file `functions_collect_parse_10Ks.R`.## S1. Download US Public Firms' SEC 10-K FilingsAlthough parsing SEC EDGAR using R package `edgar` is one way to get all SEC filings we need, we directly download raw SEC filings from the [Notre Dame Software Repository for Accounting and Finance (SRAF)](https://sraf.nd.edu/sec-edgar-data/cleaned-10x-files/).```{r googledrive_info, include=TRUE}#| label: tbl-google-drive#| tbl-cap: Google drive file information from Notre Dame SRAF # store sharing links of all files on the google drive googledrive_links <-strsplit(x ="https://drive.google.com/file/d/1G9Qyte36a-9AN8JoH79g7iioNn1AT24d/view?usp=drive_link > 10-X_2022\nhttps://drive.google.com/file/d/14zgoElxrhFJjR_oyw93WQo1AcaL-ZEsg/view?usp=drive_link > 10-X_2019\nhttps://drive.google.com/file/d/10a7myBg5h_-Vq_QkqRqjn6j6X4EOQuPp/view?usp=drive_link > 10-X_2020\nhttps://drive.google.com/file/d/10Fi5SU5LVUGq1oJz1iPWpCMwa_eAdnjD/view?usp=sharing > 10-X_2019 \nhttps://drive.google.com/file/d/10Dl_Dw2_JmMnT6tJv7duo3KOZfGUQREv/view?usp=drive_link > 10-X_2018\nhttps://drive.google.com/file/d/10DSuO8pVtjG_IyWk1k46oiIsLhwK3UiD/view?usp=sharing > 10-X_2017\nhttps://drive.google.com/file/d/10B4dOF2M1iUI6MooT7mEIJcuX6YYgLTQ/view?usp=drive_link > 10-X_2016\nhttps://drive.google.com/file/d/107dzze4B1Q9L8rb_WWMR0M_HD9zyK8W7/view?usp=drive_link > 10-X_2015", split ="\n")[[1]] %>%strsplit(split =">") %>%do.call(rbind.data.frame, args = .) %>%`colnames<-`(c("Link", "File")) %>%mutate(id =str_extract(string = Link, pattern ="(?<=/d/)[^/]+(?=/view)"), # extract the file id Year =as.integer(str_extract(string = File, pattern ="(?<=_)\\d{4}")), # extract the file year File =paste(str_trim(File, "both"), ".zip", sep ="") ) %>%select(Year, id, File)## tabulation: Table 1gt(googledrive_links) %>%tab_header(title ="Table 1: Google drive file information from Notre Dame SRAF", ) %>%tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() )```Steps and command to download file(s) in the CMD:- First, get the API key from [Oauth 2.0 Playground - Google Developers](https://developers.google.com/oauthplayground/).- [Steps](https://gist.github.com/anoopkcn/92859349a18076f198ea73888f440842): Select & authorize APIs $\rightarrow$ Drive API v3 $\rightarrow$ https://www.googleapis.com/auth/drive.readonly.- Get the `Access token` and copy to the `api_key` variable below.- Next, choose the files you want to download and use function `googledrive_download()` to generate the curl command and download the files.- Here I set the default location of downloaded file to `"/scratch/nhh/sec/"` and you can update to your own.- [The code below](#lst-googledrive_download) only needs to be run once. Alternatively, you can use `system(<!-- the curl command -->)` inside the for loop to save the storage space.::: {#lst-googledrive_download}```{r googledrive_download, eval=FALSE}# curl -H "Authorization: Bearer ya29.a0AcM612zWU6Da_xDydbg-ZDc6vBpMBUoYBTO44oTpTeDvHOhzOyjMr66xdIO7nCfclFiE_NdjSJZvdpFWsNoj2Ds-7L8O2jnrJ15I3MfYb4vlsPcxFj0tPx8Mr8MIa081ZnoIXWnvft6D4aQ1qjda4LyoCl1j0iYuNPKrN3jfaCgYKAS8SARMSFQHGX2Mi8_vM15q895m7oulKDmaIrw0175" https://www.googleapis.com/drive/v3/files/10Fi5SU5LVUGq1oJz1iPWpCMwa_eAdnjD?alt=media -o /scratch/nhh/sec/10-X_2019.zip## function to automatically generate the downloading code googledrive_download <-function(api_key, file_info, file_link, file_name, to ="/scratch/nhh/sec/") {if (missing(file_info)) { # if argument `file_info` is not provided cmd_output <-paste('curl -H "Authorization: Bearer ', api_key, '" ', "https://www.googleapis.com/drive/v3/files/", file_link, "?alt=media -o ", to, file_name, " ", sep ="") } else {# if argument `file_info` is provided if (is.data.frame(file_info) &dim(file_info)[2] ==2) { cmd_output <-paste(apply(X = file_info, MARGIN =1, FUN =function(x) paste('curl -H "Authorization: Bearer ', api_key, '" ', "https://www.googleapis.com/drive/v3/files/", x[1], "?alt=media -o ", to, x[2], sep ="") ), collapse ="; " ) } else {stop("Error: 'file_info' parameter is not data.frame object or has more than 2 columns.") } }return(cmd_output)} api_key ="ya29.a0AcM612xRrh1wolCu4ufaTDwkJqXerA0HA6CyTgLUtQJ6V0JyWeZnlCF7oYx2R8CZ9KhwFPfrdvFPG2WKcAS_8GVK_ve7VvIg-HZAxiD2Xhx4vnUcYLgWtSLMRPzdUnJS_3YmO2CDHVhY8UQDmYmJKsvkmtSElGdLqxKON64laCgYKAaISARMSFQHGX2Mi8eNrVwx4jsGnn9JrhKkexA0175"googledrive_download_cmd <-googledrive_download(api_key, file_info = googledrive_links[1, 2:3])## directly run the code in the console, instead of in the terminal system(googledrive_download_cmd)list.files(path ="/scratch/nhh/sec/", pattern =".zip") ## unzip one of the .zip file utils::unzip(zipfile ="/scratch/nhh/sec/10-X_2019.zip", exdir ="/scratch/nhh/sec/")```:::## S2. Look and Read the SEC filings.To understand the information contained in the name of the csv files, please refer to the "Paths and directory structure" section in [Accessing EDGAR Data](https://www.sec.gov/search-filings/edgar-search-assistance/accessing-edgar-data)- <mark><b>Central Index Key (CIK)</b></mark>: EDGAR assigns to filers a unique numerical identifier, known as a Central Index Key (CIK), when they sign up to make filings to the SEC. CIK numbers remain unique to the filer; they are not recycled. **It is named as `CIK` in the cleaned dataset**.- <mark><b>Accession number</b></mark>: For example, 0001193125-15-118890 is the accession number, a unique identifier assigned automatically to an accepted submission by EDGAR. The first set of numbers <u>(0001193125)</u> is the CIK of the entity submitting the filing. This could be the company or a third-party filer agent. <i>[Some filer agents without a regulatory requirement to make disclosure filings with the SEC have a CIK <u>but no searchable presence</u> in the public EDGAR database]{style="color: red;"}</i>. The next two numbers (15) represent the year. The last series of numbers represent a sequential count of submitted filings from that CIK. The count is usually, but not always, reset to zero at the start of each calendar year. It is **named as `accession_num` in the cleaned dataset**.```{r sec_filings, echo=TRUE}#| label: tbl-sec-filename#| tbl-cap: Information from File Paths of .Zip Files # list of files in the folder sec_csv <-list.files("/scratch/nhh/sec/2019", recursive=TRUE, full.names =TRUE)# set.seed(123); csv_sample <- sample(sec_csv, size = 10)# extract the list directly from .ZIP file sec_csv2 <-unzip(zipfile ="/scratch/nhh/sec/10-X_2019.zip", list =TRUE) %>%grep(pattern =".txt$", x = .$Name, value = T)# extract filing name information using `sec_filing_nameinfo()`sec_csvinfo <-sec_filing_nameinfo(file_path = sec_csv2, keep.original =TRUE) %>%as_tibble() %>%mutate(filing_date =as.Date(x = filing_date, format ="%Y%m%d"))## tabulation: Table 2set.seed(123)gt(sample_n(sec_csvinfo, size =10)) %>%tab_header(title ="Information from File Paths of .Zip Files",subtitle =md("File: 10-X_2019.zip \u2192 Variable: `sec_csvinfo`") ) %>%tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() ) %>%tab_style(style =cell_text(size =px(8)), locations =cells_body(columns =c(full_path)) ) %>%cols_width( filing_date ~cm(30) )```After getting basic information from the title of the SEC filings, we now will import the .txt file and parse required information.### s2.1. Import 10-K Filings and Familiarise the Structure```{r 10kimport, echo=TRUE, }## keep the universe of 10-K filingssec_10konly <- sec_csvinfo %>%filter(grepl(pattern ="10-K", x = file_type, fixed = T))## get the 10-K for Apple Inccat(paste("Apple Inc.>", sec_10konly %>%filter(CIK =="320193") %>% .$full_path, collapse =" "))```To extract the purchasing/outsourcing contract information as in Moon and Phillips (2020), we only need to look at 10-K filings. Currently, all 10-X filing types **include `r paste(sort(unique(sec_csvinfo$file_type)), collapse = ", ")`**, and we will drop all 10-Q related filings.This step significantly reduce the number of observations we need to examine. For instance, the total number of 10-X filings in `r str_extract(string = sec_csvinfo$full_path[1], pattern = "^\\d{4}")` drops from `r format(nrow(sec_csvinfo), big.mark = ",", scientific = FALSE)` in `sec_csvinfo` to `r format(nrow(sec_10konly), big.mark = ",", scientific = FALSE)` in `sec_10konly`.Here I start with the file `r filter(sec_10konly, CIK == "320193")$full_path` to demonstrate.##### **s2.1A. Header Info in 10-K Filings**```{r sec_headers, echo=TRUE}#| label: tbl-header-info#| tbl-cap: Header Information in 10-K Filings ## read .txt files into the R environment # filing_path <- sec_10konly$full_path[1]filing_path <- sec_10konly %>%filter(CIK =="320193") %>% .$full_path # Apple Inc: // 2488## testing candidcates: ## [ ]: https://www.sec.gov/Archives/edgar/data/1173281/000138713119000051/ohr-10k_093018.htm#ohr10k123118a010## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/831641/000083164120000154/ttek-20200927.htm (table is more complex) ## [ ]: https://www.sec.gov/Archives/edgar/data/320193/000032019323000106/0000320193-23-000106.txt ## [ ]: https://www.sec.gov/Archives/edgar/data/1045810/000104581020000010/nvda-2020x10k.htm#s82E07D2E693B525F8500B3A76673C74A## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/1652044/000165204424000022/goog-20231231.htm > Alphabet Inc. ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/2488/000000248824000012/amd-20231230.htm > AMD > search "purchase commitments" ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/1543151/000154315124000012/uber-20231231.htm > [Uber Tech. > Purchase Commitment in Text] ### Tables in Notes under Item 8. ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/0001730168/000173016823000096/avgo-20231029.htm > [Broadcom Inc. > The table is not under Item 7, but under Note 13.] ## [ ]: https://www.sec.gov/ix?doc=/Archives/edgar/data/1090727/000109072724000008/ups-20231231.htm > [UPS > Table is under Item 8, Note 9]# filing <- readLines(con = filing_path) filing <-readLines(archive::archive_read("/scratch/nhh/sec/10-X_2019.zip", filing_path))## create a more structured file for the main body of the document filing_structured <- filing[(grep("<DOCUMENT>", filing, ignore.case =TRUE)[1]):(grep("</DOCUMENT>", filing, ignore.case =TRUE)[1])] %>%paste(., collapse =" ") %>%str_squish() %>%clean_html2(input_string = ., pattern ="(</[^>]+>\\s*</[^>]+>\\s*)<([^/])") %>%# *updated Oct 10, 2024 as.vector() ## keep only the plain text in each section filing_cleantext <-sapply(X = filing_structured,FUN =function(x) html_text(read_html(x), trim =TRUE), USE.NAMES =FALSE)## get the filing headers filing_header <-filing.header(x = filing)### tabulate the header information gt(as.data.frame(`colnames<-`(filing_header, c("Item", "Input"))) ) %>%# tab_header(title = "Table 3: Header Information in 10-K Filings") %>% tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() )# ## get the table of contents (toc) # filing_toc <- filing.toc(x = filing, regex_toc = "<text>|</text>") # # browsable(HTML(as.character(filing_toc))) # view the ToC in html format ```The function `filing.toc()` does not necessarily extract the table of contents. Although we can use `regex_toc = "<table>|</table>"` to get the first table we saw in the .txt file, it may not be the table of contents we want. The function `loc.item()` is better at identify the item; however, it is not structured to get the full table of contents. We modify function `loc.item()` and create function `loc.item_MDnA()` to better extract the item we want.##### **s2.1B. All Items in 10-K filings**To see the full list of items in a 10-K filing, I look into this [file](https://www.sec.gov/answers/reada10k.htm) and extract all items. The @tbl-toc-items below presents all items included in a 10-K filing.```{r 10kitems, echo=TRUE}#| label: tbl-toc-items#| tbl-cap: Items in the Table of Contents in 10-K Filings ## This section extract the names of each items in the 10-K filing. # URL of the webpageurl <-"https://www.sec.gov/answers/reada10k.htm"# Set a custom user-agent string to mimic a browseruser_agent_string <-"leonardo.xu@gmail.com"# Read the webpage with the custom user-agentreada10k <-read_html(GET(url, user_agent(user_agent_string)))# browsable(HTML(as.character(reada10k)) )# generate the item text reada10k_items <-html_nodes(reada10k, "table")[3] %>%html_nodes(., "p") %>% .[grep(pattern =">Item\\s+[1-9]", x = ., ignore.case =FALSE)] %>%sapply(X = ., FUN =function(x) { text_raw <-str_squish(html_text(html_nodes(x, "strong, b"))) text_output <-paste(text_raw[text_raw !=""], collapse =" - ") if (!grepl("-", text_output)) { text_output <-gsub("\"|“|”|\u0093", "- ", text_output) } output <-str_replace_all(string = text_output, pattern ="\"|“|”|\u0093|\u0094", replacement ="")return(output) }, simplify =TRUE) %>%str_split_fixed(string = ., pattern =" - ", 2)# tabulate the items gt(`colnames<-`(data.frame(reada10k_items), c("Item", "Content"))) %>%# tab_header(title = "Table 4: Items in the Table of Contents in 10-K Filings") %>% tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() ) %>%cols_width( Item ~cm(30) ) %>%tab_style( # headers to boldstyle =cell_text(weight ="bold"),locations =cells_column_labels() )```From @tbl-toc-items, Item 7, MD&A, is the item of interest. We need to first locate the whole section of Item 7 and then extract the information from that. The two candidate REGEXs are:(1) <mark>"(?=.*purchas)(?=.*(obligation\|commitment\|agreement\|order\|contract))"</mark>(2) <mark>"\\bpurchas\[\^\\\\.\]\*\\b(obligat\|commitment\|agreement\|order\|contract)"</mark>and the second is faster while the first is more general. Next, we extracted information from identified Items. ### s2.2. Information about Purchase Obligation DisclosureSEC publishes the final rule on [Disclosure in Management's Discussion and Analysis About Off-Balance Sheet Arrangements and Aggregate Contractual Obligations](https://www.sec.gov/rules-regulations/2003/01/disclosure-managements-discussion-analysis-about-balance-sheet-arrangements-aggregate-contractual) in 2003. The required [table of contractual obligations](https://www.federalregister.gov/d/03-2365/p-150) includes the following four categories of contractual obligations:- Long-term debt obligations;- Capital lease obligations;- Operating lease obligations;- Purchase obligations; and- Other long-term liabilities reflected on the registrant's balance sheet under GAAP.However, this information is not only disclosed in Item 7, but also in the Note(s) in Item 8. E.g. [Apple Inc. 2019 10K](https://www.sec.gov/ix?doc=/Archives/edgar/data/0000320193/000032019319000119/a10-k20199282019.htm).::: {#tip-purchase-obligations .callout-tip collapse="false"}### About the Lack of Consistency in the Reporting Format!The purchase obligation disclosure is not always tabulated and can sometimes be in plain text. Here is one example from [Apple's 10-K filing in 2023](https://www.sec.gov/ix?doc=/Archives/edgar/data/320193/000032019323000106/aapl-20230930.htm). Even though Apple tabulates these numbers in its previous filings, there is no guarantee that they will continue the same reporting format.:::So, we start with Item 7:function `loc.item_MDnA()` is created to locate the MD&A section in the 10-K filing. ```{r purchase_obligation_item7, echo=TRUE}## Item 7: # cat("Information to locate Item 7 in the 10-K filing:") loc_item7 <-loc.item_MDnA(x = filing_structured, filing_type ="10-K")## Extract the table: ### From Item 7: item7_purchase <-filing.10kitem_purchase(x = filing_structured,loc_item = loc_item7$loc_item, item_regex ="(?=.*purchas)(?=.*(obligation|commitment|agreement|order|contract))")```We can see from variable `loc_item7` that Line `r paste(loc_item7$loc_item, collapse = " to ")` in the cleaned raw HTML variable `filing_structured` are for Item 7. Then, we use function `filing.10kitem_purchase()` to obtain the purchase obligation information in variable `item7_purchase`. As shown in Table @tbl-item7-purchase, the purchase obligations are detailed below. Unit measure, plain text and raw HTML can also be found in `item7_purchase`. ```{r purchase_obligation_item7table, echo=FALSE} #| label: tbl-item7-purchase#| tbl-cap: Purchae Obligation Table in Item 7## tabulate the table from Item 7: gt(data.frame(item7_purchase$table) %>%arrange(item)) %>%# tab_header(title = "Table 4: Items in the Table of Contents in 10-K Filings") %>% tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() ) %>%tab_style(style =cell_text(color ="red"), locations =cells_body(columns =c(item), rows =grepl(pattern ="\\bpurchas[^\\.]*\\b(obligat|commitment|agreement|order|contract)",x = item, perl =TRUE) ) ) %>%tab_style( # headers to boldstyle =cell_text(weight ="bold"),locations =cells_column_labels() ) %>%tab_footnote(footnote =paste("Unit:", gsub(pattern ="[\\(\\)]", replacement ="", x = item7_purchase$table_unit), collapse =""), locations =cells_column_labels(columns = value) ) ```Then, we look into Item 8. We still use function `loc.item_MDnA()`. Different from searching Item 7, we adjust the two parameters `regex_item` and `regex_num` in the function to locate Item 8. ```{r purchase_obligation_item8, echo=TRUE}## Item 8: loc_item8 <-loc.item_MDnA(x = filing_structured, filing_type ="10-K", regex_item =c(NA, "(?=.*finan)(?=.*statem)(?=.*supple)(?=.*data)"), # item header regex_num =c("[>](Item|ITEM)[^0-9]+2\\.", "[>](Item|ITEM)[^0-9]+8\\."), # item number regex_perl =TRUE) item8_notes_html <-filing.item8_notes(x = filing_structured, loc_item = loc_item8$loc_item, item_regex ="\\bpurchas[^\\.]*\\b(obligat|commitment|agreement|order|contract)",note_regex =NULL) ## Extract the table: ### From Item 8: item8_purchase <-sapply(X = item8_notes_html, FUN =function(x) {filing.10kitem_purchase(x = x,loc_item =c(1, length(x)),item_regex ="(?=.*purchas)(?=.*(obligation|commitment|agreement|order|contract))")}, simplify =FALSE, USE.NAMES =TRUE)#### further assign each element in the list into a single variable.{for (x inseq_along(item8_notes_html)) {print(paste("item8", letters[x], "_purchase", sep =""))assign(x =paste("item8", letters[x], "_purchase", sep =""),value = item8_purchase[[x]]) } rm(item8_purchase) # remove the collection if it contains more than 1. } ```We can see from variable `loc_item8` that Line `r paste(loc_item8$loc_item, collapse = " to ")` in the cleaned raw HTML variable `filing_structured` are for Item 8. After locating Item 8, function `filing.item8_notes()` is used to (1) Extract the HTML for Item 8 and create of a Table of Notes ("ToN"). (2) Identify the Note(s) that match the `item_regex`. Alternatively, the Note(s) can be extracted by `note_regex`. (3) Return the HTML for the [<u>sub-Note</u>]{style="color: red;"} in the Note(s) of Interest. The output of function `filing.item8_notes()` is a list with the name of the element being the Note name and element is a character vector recording the raw HTML for the sub-Note(s). ::: {#wrn-filing.item8_notes .callout-warning collapse="false" .column-margin}### Additional Notes for function `filing.item8_notes()` This additional step of using this function is to extract the header of the sub-Note and use it as the name of the "item" variable in the final output. As you can see from the function name, it is for [<b>Item 8</b>]{style="color: red;"} only. ::: Output `item8_notes_html` contains information about the matched sub-Note HTML of corresponding Note(s). Then, we use elements in `item8_note_html` as the input in function `filing.10kitem_purchase()` and obtain output `item8_purchase`, which is a list. We can also choose to rename each element in the list separately. Using code `ls(pattern = "item\\d(\\w)*_purchase")`, we can find that variables containing purchase obligation information are ```{r purchase_oblgation_all, echo=FALSE}ls(pattern ="item\\d(\\w)*_purchase")```As shown in Table @tbl-item8-purchase, the purchase obligations are detailed below. Unit measure, plain text and raw HTML can also be found in `item8a_purchase`. ```{r purchase_obligation_item8table, echo=FALSE} #| label: tbl-item8-purchase#| tbl-cap: Purchae Obligation Table in Item 8 ## tabulate the table from Item 7: gt(data.frame(item8a_purchase$table) %>%arrange(item)) %>%# tab_header(title = "Table 4: Items in the Table of Contents in 10-K Filings") %>% tab_options(table.font.size =10, heading.align ='left' ) %>%tab_style( # update the font size for table cells. style =cell_text(size =px(10)),locations =cells_body() ) %>%tab_style(style =cell_text(color ="red"), locations =cells_body(columns =c(item), rows =grepl(pattern ="\\bpurchas[^\\.]*\\b(obligat|commitment|agreement|order|contract)",x = item, perl =TRUE, ignore.case =TRUE) ) ) %>%tab_style( # headers to boldstyle =cell_text(weight ="bold"),locations =cells_column_labels() ) %>%tab_footnote(footnote =paste("Unit:", gsub(pattern ="[\\(\\)]", replacement ="", x = item8a_purchase$table_unit), collapse =""), locations =cells_column_labels(columns = value) ) ```## S3. Up Next! With all functions presented in this document, I will write the parallel functions to parse information from all files. Let's start with the 2019 filings. Here is a list of functions used in the file: ```{r herewego, echo=TRUE}lsf.str(){## information extraction from function `fling.cleaned()` info <- filing_header selected_headers <-c('ACCESSION NUMBER','CONFORMED SUBMISSION TYPE','PUBLIC DOCUMENT COUNT','CONFORMED PERIOD OF REPORT','FILED AS OF DATE','DATE AS OF CHANGE','FILER:','COMPANY DATA:','COMPANY CONFORMED NAME','CENTRAL INDEX KEY','STANDARD INDUSTRIAL CLASSIFICATION','IRS NUMBER','STATE OF INCORPORATION','FISCAL YEAR END','FILING VALUES:','FORM TYPE','SEC ACT','SEC FILE NUMBER','FILM NUMBER','BUSINESS ADDRESS:','STREET 1','STREET 2','CITY','STATE','ZIP','BUSINESS PHONE') info_cleaned <- info[match(selected_headers, table = info[1:max(grep("mail", info[,1], ignore.case = T)[1]-1, nrow(info), na.rm = T),1]), 2] # all info before section "MAIL ADDRESS:" info_cleaned## generate cleaned info item2_cleaned <-filing.item(x = filing_structured,loc_item = loc_item7$loc_item,item_id = loc_item7$item_id,item = loc_item7$item,item_id_backup = loc_item7$item_id_backup, ## updated August 8, 2023 text_break_node = text_break_node, reporting_qrt = info_cleaned[4],parts ="footnote")}```------------------------------------------------------------------------## Notes 1. All codes here may have issues with pure text documents, i.e. filings are not in the HTML format. 2. A new set of codes need to be written to identify whether the filing is in HTML or TEXT format. 3. This situation should be a minority in the whole sample, but still need to be checked. ------------------------------------------------------------------------## Appendix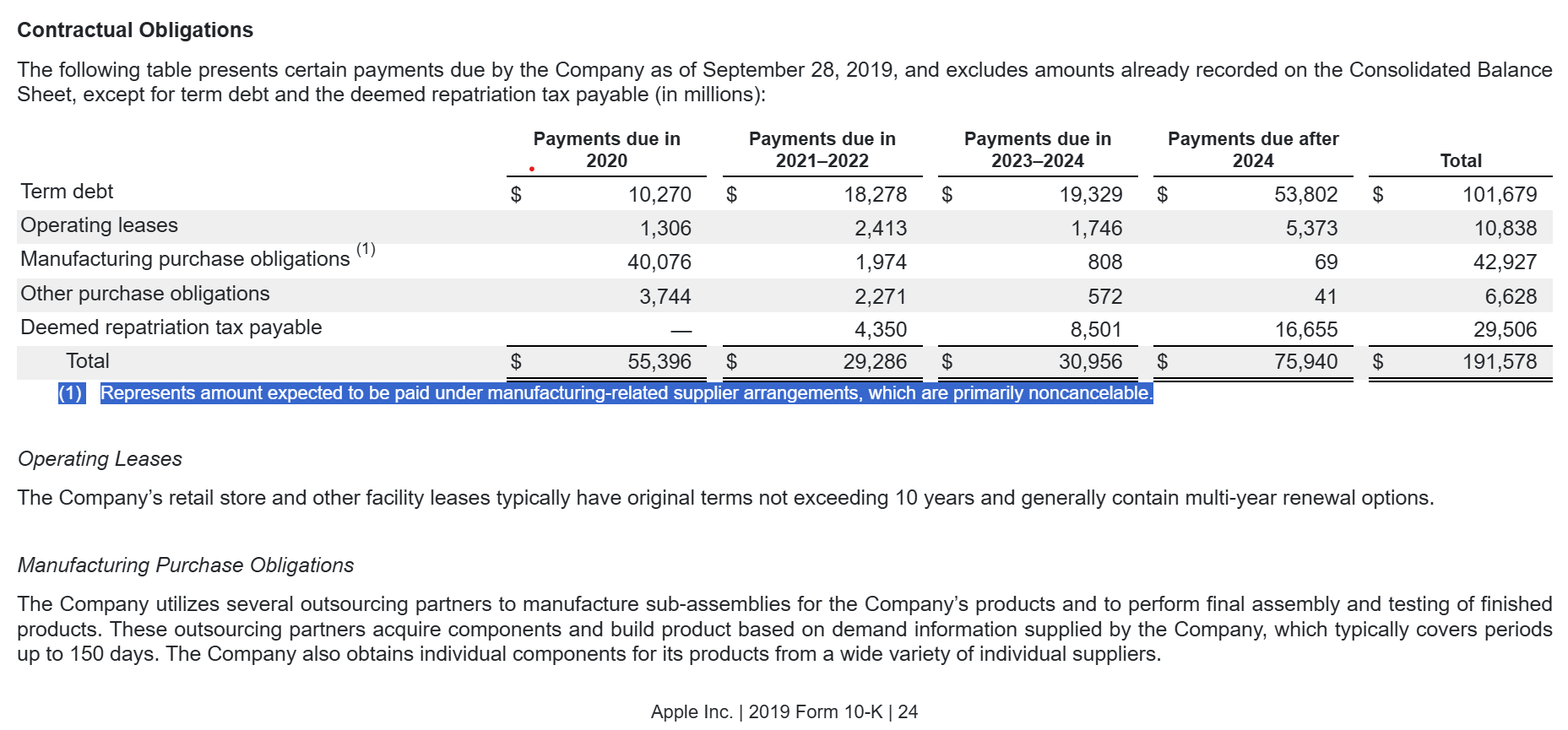{#fig-apple_2019_10K fig-alt="footnote indicates manufacturing obligations are primarily non-cancelable."}The footnote (1) in @fig-apple_2019_10K shows that manufacturing purchase obligations are primarily non-cancellable, which indicates that some numbers of the purchase obligations may not cover items consistent with our story.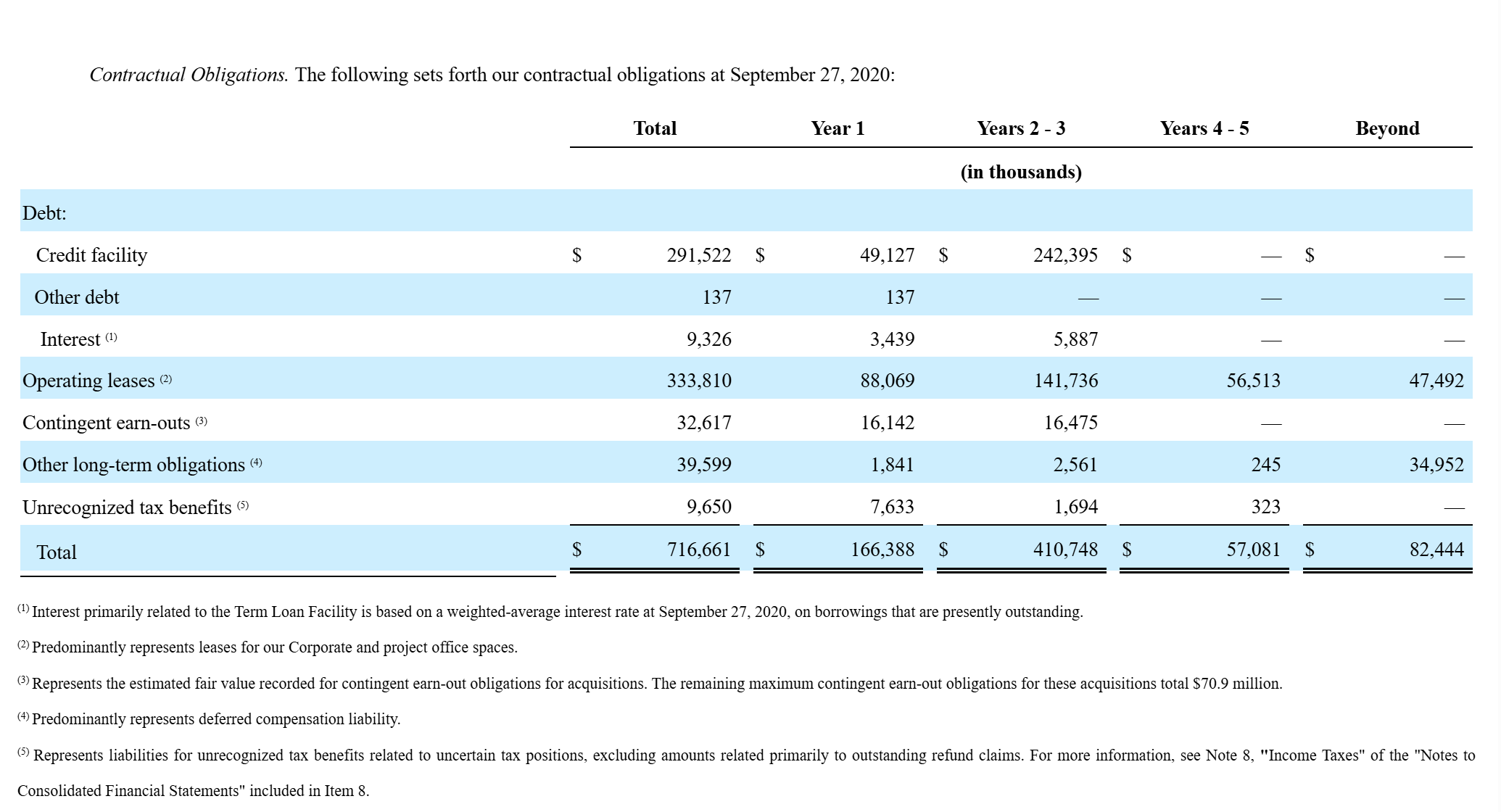{#fig-tetra_2020_10K fig-alt="No purchase contract is found and more advanced function is needed to parse this kind of tables."}{#fig-karbonX_2024_10K fig-alt="Smaller reporting companies defined under Item 10 of Regulation S-K are not required to disclose contractual obligations under Item 7. You need to find a way to separate these filings from the very beginning to improve the parsing efficiency."}The underlined paragraph in @fig-karbonX_2024_10K shows that smaller reporting companies defined under Item 10 of Regulation S-K are not required to disclose contractual obligations under Item 7. <i>[You need to find a way to separate these filings from the very beginning to improve the parsing efficiency]{style="color: red;"}</i>.## Reference


